Multilayer perceptrons (neural networks)
Recenlty, I have built a fully-connected multilayer perceptron(MLP) and trained this MLP to recognize handwritten digits. Therefore, in this blog post I want to talk about what a Multilayer Perceptron is and what the basic idea behind it is.
A Multilayer Perceptron is a neural network where perceptrons are structured in multiple layers as you can see in the picture below. A MLP consists of at least 2 layers. One input layer, zero to multiple hidden layers and one output layer. An MLP is a fully connected neural network, which means that every perceptron in one layer is connected to every perceptron in the next layer (see picture below). A MLP is used for supervised learning. With supervised learning, we try to train a model to classify inputs knowing what kind of outputs we can expect. Training a MLP to recognize digits is an example of supervised learning.
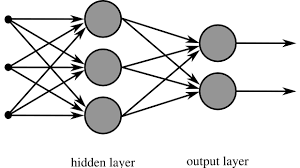
A MLP takes input in the form of a list of numbers between 0 and 1. These inputs will be directly propagated from the input layer to the first hidden layer without any calculations. These perceptrons will use all the input to calculate the output of the perceptron which will on his turn be propagated to all perceptrons in the next layer until we have arrived at the output perceptrons. Each output perceptron in the MLP represents one of the possible objects the input can be classified to. The output is also a list of numbers between 0 and 1. The closer the output is to 1, the more certain we are that the input can be classified to a specific object and the closer the output is to 0, the more certain we are that the input is not that specific object.
To set up the MLP, we first need to decide how many perceptrons the input and output layer have, how many hidden layers we have and what the size of these layers are. The number of input perceptrons is simply the size of the input list and the number of output perceptrons is the amount of different objects we can classify the input to. So if we look for example at the problem of recognizing handwritten digits, where we use pictures of 24x24 pixels, then we should have 576 (24x24) input perceptrons, because every pixel is a part of the input. The number of output perceptrons is 10, because we have 10 different objects (0-9) that we can classify to. Making a decision about the hidden layer is a bit more complicated, but for most problems, we only need one hidden layer and the amount of perceptrons in the hidden layer should be less than the amount of input perceptrons and more than the amount of output perceptrons. To get the perfect amount of perceptrons in the hidden layer, you could experiment with different amounts and check which amount gives the best result.
So how does a perceptron use its input to calculate the output. First, a perceptron has multiple weights. The amount of weights is equal to the amount of inputs. A perceptron multiplies each weight with one of the inputs and calculates the total sum of this. This number is put in an activation function. Normally the activation function is the sigmoid function. The result of this activation function is also the output of the perceptron. To get the output of a whole MLP, we just perform the above mentioned process on every perceptron and pass the output as input to all perceptrons in the next layer, until we are at the output perceptrons. This process is called feedforward.
To train one single perceptron, we will calculate the error of the perceptron using the output and desired output. Using this error, we can change the weights in the perceptron using a formula so that next time we run the perceptron using the same input, the error will be decreased. To train a whole MLP, we use a method called backpropagation where we calculate the error of each output perceptron and backpropagates this error to each perceptron in the previous layer using a formula to change the weights of all perceptrons in the previous layers.
To train a MLP to classify input to the correct output, you need to have a dataset which you can use to train the MLP. For example, if you want to train the MLP to recognize handwritten digits, you will need a dataset which contains many different variations of how you can write each digit. This variation is very important, because if your dataset only contains data where each digit is written exactly the same, the MLP will only be good at classifying input if it is written in exactly the way it is written in the dataset, but not if it has been written a bit different. Therefore it is important to have variation in your dataset. To train the MLP, you need to use this dataset and train the MLP the way I explained in the previous paragraph using each object in the dataset for a few iterations.
So this is the basic idea of how a MLP works. Of course, there are many more questions we need to answer like how do you actually feedforward the output and backpropagate the error and how do you decide how many hidden layers a MLP should have. That is something I will talk about some other time, but after reading this, you should have an basic idea of how a multilayer perceptron works.